【網站 搜尋排名 SEO 輔助工具軟體】Screaming Frog SEO Spider 7.2 正式版
網站搜尋排名 SEO 是網站經營者兵家必爭之地!
如果您還在使用『人工方式』處理與分析網站的連結,那將會『不死也剩下半條命』!
其實,網站的經營不必那麼辛苦!
『總教頭』一直告訴大家:網站數據要能善用『程式軟體』去處理,那才會:事半功倍!
一個網站內的連接是否正確,對該網站在搜尋引擎上的排名會有一定的影響。
為什麼呢?
我們從一個訪客的角度來看:
若您在某個網站上點選了一個連接後看到了錯誤的訊息,您會不會覺得該網站的水準不如何?
同樣的道理,若一個網站內有錯誤的連接,搜尋引擎也會因此降低該網站的排名,因為錯誤的連接會讓訪客有不好的經驗。
若您的網站不大,那一個查詢所有連接是否正確的方式是每一頁的每一個連接都去點一次。可是,對大部分的站長來說,這樣的做法會花費太多時間。
在這時候,我們需要一個能夠像搜尋引擎 spider 一樣的工具。該工具將可以爬行過網站內的所有網頁,並且確認每一個網頁內的每一個連接是否有問題。
這一類的工具一直都存在,而最有名的是 Xenu Link Sleuth。
【總教頭】也有用過這個工具,可是我覺得這工具並不好用,所以用過了一兩次後就沒有再用了。
來!【總教頭】推薦您一個新的工具: Screaming Frog 公司出的 SEO Spider。
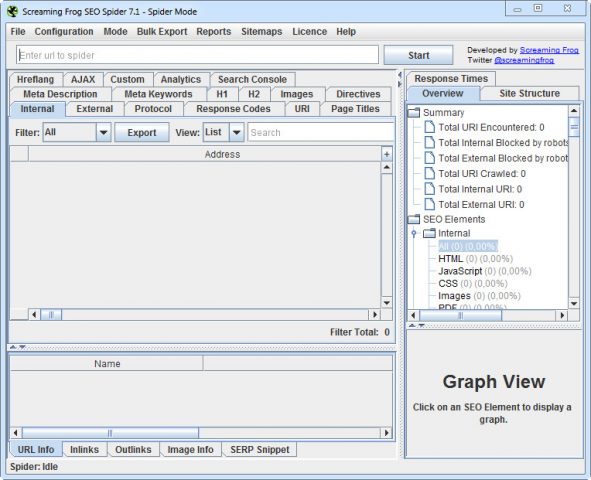
【網站 搜尋排名 SEO 輔助工具軟體】Screaming Frog SEO Spider 7.2 正式版 官方網址:
https://www.screamingfrog.co.uk/
Screaming Frog SEO Spider 的用法很簡單,只要打入一個網頁的URL,該工具就會去以該網頁當起點去爬行該網站內的網頁。
若您用的是正式的版本,那您可以自己決定一次爬行多少頁。
爬行完畢之後該工具會告訴我們該次爬行過網頁的以下的資訊:
網址
文件類別 (例如是文字檔或是JPG檔)
HTTP 狀態碼 (Status Code) 和狀態
Page Title 和 Page Title 的長度
Meta Description 和 Meta Description 的長度
Meta Keywords 和 Meta Keywords 的長度
H1 和 H1 的長度
H2 和 H2 的長度
Canonical URL
文件大小
層次 (第1層就是從輸入的網址內點選一個連接就可以到達,第2層就是要點選兩次才能到達,以此類推)
對於所有的外向連接,這個工具能夠提供以下的資訊:
連接出去的網址
連接出去的文件類別 (例如是文字檔或是JPG檔)
連接出去的 HTTP 狀態碼 (Status Code) 和狀態
層次 (第1層就是從輸入的網址內點選一個連接就可以到達,第2層就是要點選兩次才能到達,以此類推)
若您看到連接出去的HTTP狀態碼是400開頭的,那就代表該連接有錯誤,需要改正。除此之外,其他許多的訊息也都是很有用的。
舉例來說,如果您覺得每個網頁都需要有一個 canonical URL,那這個工具就可以讓您一目了然地看出來是不是所有的網頁都有設定 canonical URL。
——————————————
Screaming Frog SEO Spider — 特別為SEO設計,並作為一個有用的工具來分析網站。
尋找破碎的連結:
立即抓取網站,找到中斷的連結(404)和伺服器錯誤。批次匯出錯誤和源網址以進行修復或傳送給開發人員。
審核重定向:
在網站遷移中尋找臨時和永久重定向,識別重定向鍊和迴圈,或上傳要審核的網址清單。
分析頁面標題和元資料:
在抓取過程中分析頁面標題和元描述,並確定您的網站中過長,縮短,缺失或重複的內容。
發現重複的內容:
使用md5算法檢查發現完全重複的網址,部分重複的元素(如網頁標題,說明或標題)以及尋找低內容網頁。
使用XPath提取資料:
使用CSS路徑,XPath或正則表達式從網頁的HTML收集任何資料。這可能內含社交元旗標,附加標題,價格,SKU或更多!
審查機器人和指令:
檢視robots.txt,元資料機器人或X-Robots-Tag指令(例如「noindex」或「nofollow」)以及規範和rel =「next」和rel =「prev」阻止的網址。
生成XML站台地圖:
快速建立XML站台地圖和圖像XML站台地圖,並對包括的URL進行進階配置,最後修改,優先級和變更頻率。
與Google Analytics(分析)整合:
連線到Google Analytics(分析)API,並針對抓取抓取使用者資料,例如會話或跳出率和轉化次數,目的,交易和收入。
Screaming Frog SEO Spider – especially designed both for SEO and serves as a useful tool to analyze websites.
Find Broken Links
Crawl a website instantly and find broken links (404s) and server errors. Bulk export the errors and source URLs to fix, or send to a developer.
Audit Redirects
Find temporary and permanent redirects, identify redirect chains and loops, or upload a list of URLs to audit in a site migration.
Analyse Page Titles & Meta Data
Analyse page titles and meta descriptions during a crawl and identify those that are too long, short, missing, or duplicated across your site.
Discover Duplicate Content
Discover exact duplicate URLs with an md5 algorithmic check, partially duplicated elements such as page titles, descriptions or headings and find low content pages.
Extract Data with XPath
Collect any data from the HTML of a web page using CSS Path, XPath or regex. This might include social meta tags, additional headings, prices, SKUs or more!
Review Robots & Directives
View URLs blocked by robots.txt, meta robots or X-Robots-Tag directives such as ‘noindex’ or ‘nofollow’, as well as canonicals and rel=“next” and rel=“prev”.
Generate XML Sitemaps
Quickly create XML Sitemaps and Image XML Sitemaps, with advanced configuration over URLs to include, last modified, priority and change frequency.
Integrate with Google Analytics
Connect to the Google Analytics API and fetch user data, such as sessions or bounce rate and conversions, goals, transactions and revenue for landing pages against the crawl.
Home Page – https://www.screamingfrog.co.uk